Warning: Use of undefined constant memo - assumed 'memo' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 278
홍차넷
Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 34
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 45
Warning: Use of undefined constant r - assumed 'r' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 47
Warning: Use of undefined constant r - assumed 'r' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 51
Warning: Use of undefined constant memo - assumed 'memo' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 237

Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 34
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 45
Warning: Use of undefined constant r - assumed 'r' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 47
Warning: Use of undefined constant r - assumed 'r' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/outlogin_toby.php on line 51
Warning: Use of undefined constant memo - assumed 'memo' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 237
Warning: Use of undefined constant is_admin - assumed 'is_admin' (this will throw an Error in a future version of PHP) in /home/redtea/html/zero_header.php on line 269
Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/zero_header.php on line 300
Warning: Use of undefined constant title - assumed 'title' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/bbs_title.php on line 16
뉴스
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/bbs_title.php on line 21
Warning: Use of undefined constant header - assumed 'header' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/bbs_title.php on line 31
- 새로운 뉴스를 올려주세요.
Warning: Use of undefined constant use_formmail - assumed 'use_formmail' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 519
Warning: Use of undefined constant use_category - assumed 'use_category' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/include/print_category.php on line 9
전체기타정치IT/컴퓨터방송/연예스포츠경제문화/예술사회게임의료/건강과학/기술국제외신
Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/setup.php on line 29
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/setup.php on line 41
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 398
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant subject - assumed 'subject' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 402
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 403
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 405
Warning: Use of undefined constant total_comment - assumed 'total_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 406
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 2
Warning: Use of undefined constant HTTP_HOST - assumed 'HTTP_HOST' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/memo_replace.php on line 3
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 10
Warning: Use of undefined constant use_category - assumed 'use_category' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 40
| Date |
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 53 17/10/19 07:10:12 Warning: Use of undefined constant mod_date - assumed 'mod_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 56 |
| Name | 구밀복검 |
| File #1 | AKR20171018131600017_02_i_20171019020118403.jpg (55.0 KB), Download : 7 |
| Subject | 스스로 바둑 깨우친 '알파고 제로' 나왔다…'AI 신기원' |
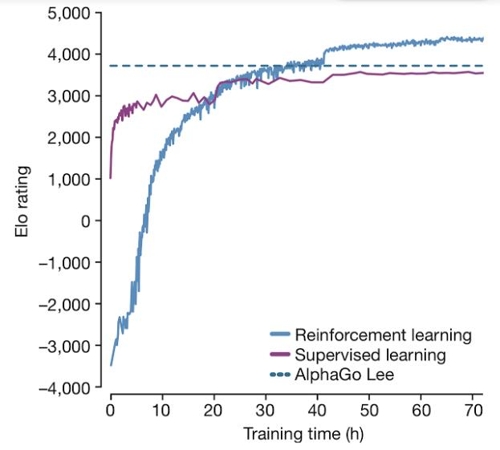 http://www.yonhapnews.co.kr/bulletin/2017/10/18/0200000000AKR20171018131600017.HTML (전략)....알파고 제로는 교과서나 기보는커녕 대국 상대조차 없이 순수한 독학으로 바둑을 익혔는데도, 인간 고수들과 기존 알파고 버전들을 압도하는 능력을 갖추게 됐다. 이는 인간이 미리 정해 놓은 정석을 외우거나 기보를 학습하는 방식으로 바둑을 배웠던 기존 버전들과는 다른 점으로, '인간의 한계를 뛰어넘는' 인공지능 연구의 중요한 이정표가 될 것이라고 연구진은 강조했다...(후략) 그래프가 충격적이네요. 인간에게 배우는 게 당장은 빨리 실력이 늘지만 얼마 안 가서 인간에게 배우지 않은 쪽이 역전한다는 것을 보여줍니다. 자연지를 인간에게 배우는 건 언발에 오줌누기일 뿐 좆되는 길이로구나..지능이 '인간' 당했네. 레퍼런스는 Mastering the game of Go without human knowledge 네요. 논문 주소 : https://www.nature.com/nature/journal/v550/n7676/full/nature24270.html ------ 댓글 추천 받고 칼럼 링크 추가합니다. https://brunch.co.kr/@madlymissyou/18 Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 133 Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 146 Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view.php on line 161 2 이 게시판에 등록된 구밀복검님의 최근 게시물
|
|
Warning: Use of undefined constant memo - assumed 'memo' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 185
Warning: Use of undefined constant use_comment - assumed 'use_comment' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 540
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 542
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 543
Warning: Use of undefined constant memo - assumed 'memo' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 545
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 576
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 577
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 577
Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 577
Warning: Use of undefined constant grant_delete - assumed 'grant_delete' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 577
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 429
Warning: Use of undefined constant use_formmail - assumed 'use_formmail' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 605
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 599
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 599
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 600
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 600
Warning: Use of undefined constant is_admin - assumed 'is_admin' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 605
Warning: Use of undefined constant is_admin - assumed 'is_admin' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 605
Warning: Use of undefined constant is_admin - assumed 'is_admin' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 609
Warning: Use of undefined constant is_admin - assumed 'is_admin' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 609
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 614
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 616
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 618
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/lib.php on line 618
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 612
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 612
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 620
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 628
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 628
Warning: Use of undefined constant HTTP_HOST - assumed 'HTTP_HOST' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 640
Warning: Use of undefined constant name - assumed 'name' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 644
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 646
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/view.php on line 646
Warning: Use of undefined constant HTTP_HOST - assumed 'HTTP_HOST' (this will throw an Error in a future version of PHP) in /home/redtea/html/pb/cmt_replace.php on line 3
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 6
Warning: Use of undefined constant file_name - assumed 'file_name' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 28
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 65
26538 class="iamcmt" style="display:none;"> Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 66
26538 class='vcm '>
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 70
Warning: Use of undefined constant x - assumed 'x' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 71
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 76
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 117
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 118
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 119
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 120
Warning: Use of undefined constant ismember - assumed 'ismember' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 121
26538'> CONTAXS2
Warning: Use of undefined constant mod_date - assumed 'mod_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 133
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 140
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 140
Warning: Use of undefined constant reg_date - assumed 'reg_date' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 142
17/10/19 07:25
26538>삭제 주소복사
Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 150
기원도 안다녔다고요?
Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 158
Warning: Use of undefined constant password - assumed 'password' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 166
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 171
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 172
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 172
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 173
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 173
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 173
Warning: Use of undefined constant level - assumed 'level' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 158
Warning: Use of undefined constant password - assumed 'password' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 166
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 171
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 172
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 172
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 173
Warning: Use of undefined constant no - assumed 'no' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 173
Warning: Use of undefined constant vote - assumed 'vote' (this will throw an Error in a future version of PHP) in /home/redtea/html/a_skin/bbsd/view_comment.php on line 173
26538>
26538>






